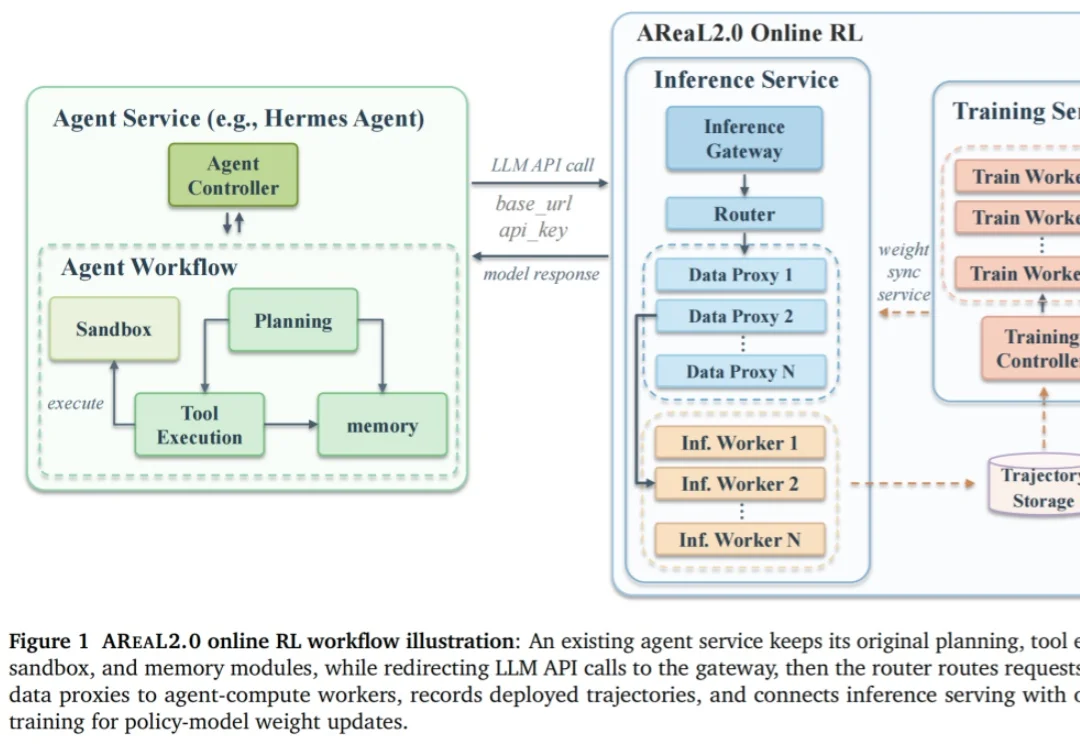
Agent的自演进,被刚刚开源的AReaL 2.0按下了加速键
Agent的自演进,被刚刚开源的AReaL 2.0按下了加速键当 Agent 从演示视频中的炫技片段开始走进真实工作流与生产环境,下一阶段的「何去何从」成为业界关注的焦点。
来自主题: AI技术研报
5978 点击 2026-07-02 14:31
 搜索
搜索
当 Agent 从演示视频中的炫技片段开始走进真实工作流与生产环境,下一阶段的「何去何从」成为业界关注的焦点。
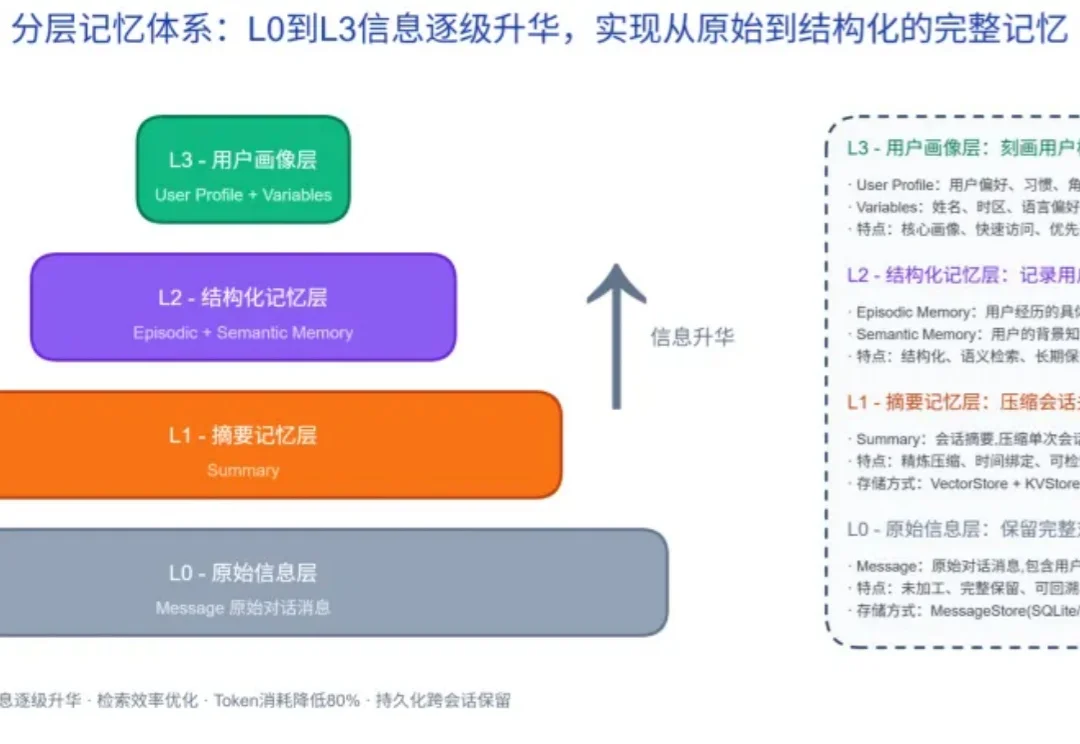
当大模型应用进入深水区,决定一个 Agent 体验上限的,早已不只是 "答得对不对", 而是 "能不能持续记住同一个人"。
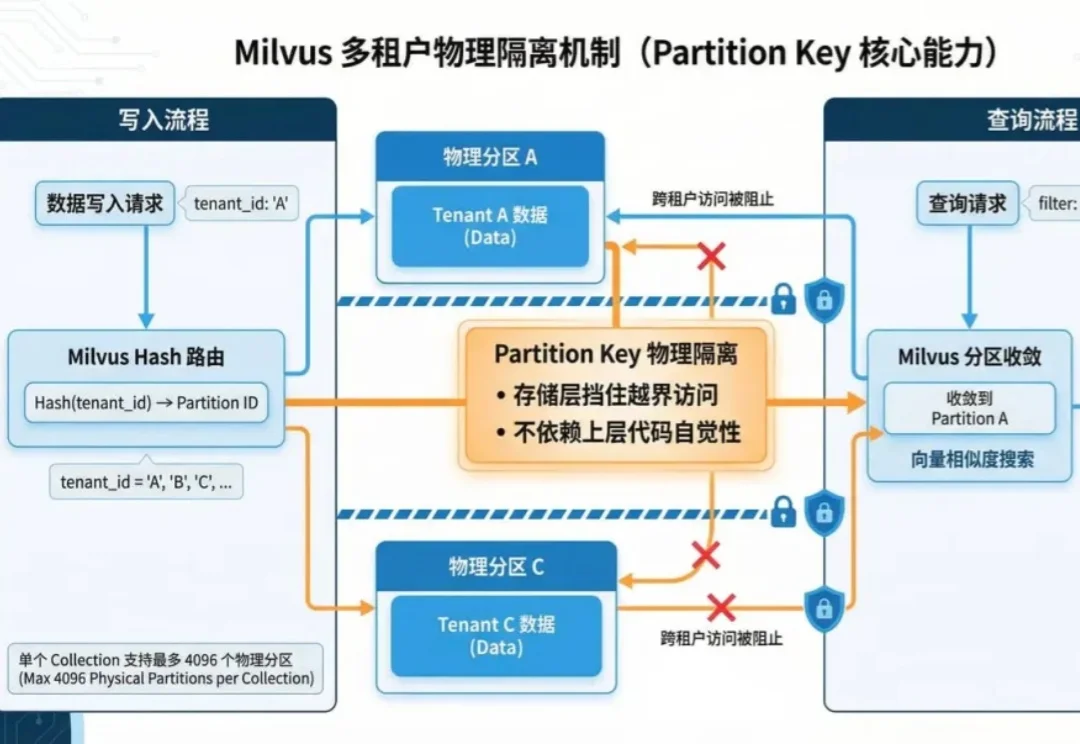
多租户 RAG 与Agent系统的生产实践中,最致命的事故莫过于数据串租,系统将租户 B 的私有数据作为背景知识,回答了租户 A 的提问。

本篇文章根据我在本月 43 Talks 线下活动中的分享整理而成。主理人李继刚邀请我时,给的主题词只有一个:Context。我想从 Agent 的视角出发,讨论一个判断:随着模型和 Harness 逐步趋同,真正决定 Agent 能力边界的,会越来越是 Context。

微信和企业微信的 Agent,同时出牌。

如果只看标题,它很容易被归到“又一个万亿参数大模型”的队伍里:1.6 万亿总参数、MoE 架构、100 万 token 上下文、面向代码和 Agent 场景。但这次真正值得看的,不只是模型有多大,而是它背后的三个问题:国产算力能不能支撑前沿级大模型训练?

Agent 正在逐渐获得「人权」。
为了想清楚 Agent 时代怎么发社交平台,我做了 ArcSocial 。ArcSocial 不是为了让 AI 替我写文章,而是为了把人的判断、Agent 的协作和平台发布流程组织成可追溯、可维护的工作区。
这款 AI 邮箱客户端 2025 年 4 月才正式上线,总生命周期不过 17 个月。Notion 给出的理由很直接,随着 Agent 能力变得更强,越来越多用户将邮件工作流交给 Agent 处理。"如今,超过一半的 Notion Mail 用户在不打开收件箱的情况下管理邮件。因此,我们决定全面转向由 Agent 来管理你的收件箱。"

15 个来自火山引擎 V-START 加速器的项目,横跨具身智能、AI 陪伴硬件、Agent 工具、内容生成、AI 教育等赛道。都在各自的场景里,把模型能力变成了用户愿意持续使用甚至付费的产品体验,要么扎进了模型短期内替代不了的物理世界,要么在垂直场景里把 Agent 做到了用户真正愿意持续用的程度,要么用 AI 重构了一个原本就有刚需的消费品类。